Sameer Ambekar
Deep learning | Computer vision

I am pursuing my Ph.D. (Doctoral Researcher) at Technical University of Munich (TU Munich) and Helmholtz Munich in Deep learning under Prof. Dr. Julia Schnabel. Additionally, fully funded by elite Konrad Zuse School of Excellence in Reliable AI (relAI) and affiliate member of Munich Center for Machine Learning (MCML). For my Ph.D at TUM, I work on Adapting Vision and Language models with GRPO (Group Refinement Policy Optimization) and adapting at Test-time.
Currently, I am conducting a research stay at Stanford University under Prof. Dr. Akshay Chaudhari, where I focus on test-time thinking for medical imaging.
My academic journey includes Masters in Artificial Intelligence (MSc AI) at the University of Amsterdam (UvA) and also worked as Research Intern at the university research AIM lab, UvA. For MSc AI thesis, I addressed Test-Time Adaptation of classifiers for Domain Generalization utilizing Meta learning, Variational inference for efficient multi-source training and transferrable features under Prof. dr. Cees Snoek, Prof. Xiantong Zhen and Zehao Xiao.
Before MSc AI, I worked as Research Assistant at IIT Delhi India under Prof. Prathosh A.P. in domain adaptation through Generative Latent search in the VAE latent space. Before working as RA at IITD, I worked at Indian Council of Medical Research (ICMR) as a Researcher under Dr. Subarna Roy (Scientist G), and Mr. Pramod Kumar (Scientist C).
Additionally, I also serve as a Reviewer at top-tier conferences and journals such as NeurIPS, CVPR, ICML, ECCV, ICCV, WACV, IEEE TNNLS, Elsevier Applied soft computing, Elsevier Neural Networks and Program Committee of AAAI conference. Furthermore, serve as a Mentor for Neuromatch deep learning course.
Teaching & Supervision at TU Munich
MSc Thesis & Project Supervision
I am particularly interested in topics such as Adapting foundation models, Vision and Language Models (VLMs), Fine-tuning, Reasoning, and related areas (not limited to these). For MSc thesis or project supervision, you are welcome to reach out to me directly.
Current Students
- • Tim Nielen - MSc Informatics, TUM · The Dynamics of Entropy Minimization for Medical Imaging
- • Andras Gaspar - BSc, TU Munich
Seminars & Courses at TU Munich
We are organizing a seminar "From General to Clinical: Adapting Foundation Models for Medical Images" for master's students. Slides
We organized a seminar "From General to Clinical: Adapting Foundation Models for Medical Images" for master's students.
News
Research Stay at Stanford University - adapting Vision-Language Models to unseen tasks.
Supervising Master's and Bachelor's students at TU Munich on entropy minimization in medical imaging.
Organized seminar on Adapting Foundation Models for Medical Imaging for MSc Informatics at TUM.
Hierarchical learning with Task Vectors accepted at WACV 2026 [Algorithms track].
MSc AI thesis methods accepted at WACV 2025 and CoLLAs 2024.
Won Best Paper Award at MICCAIw ADSMI for Selective Test-time Adaptation.
Attended ICVSS Computer Vision summer school, Sicily, Italy.
Attended EEML 2023 Machine Learning summer school by Google DeepMind.
Research Goal & Publications
Research Goal
My research centers on leveraging fundamental deep learning and machine learning techniques to address distribution shifts, a critical challenge when deploying models in real-world, ever-changing environments.
Current focus: Adapting Vision-Language Models (VLMs) with reasoning abilities using GRPO (Group Refinement Policy Optimization) and test-time strategies.
Core areas: Test-time adaptation, Domain Generalization, and Domain Adaptation, through variational inference, meta-learning, surrogate model updates, and model predictions.
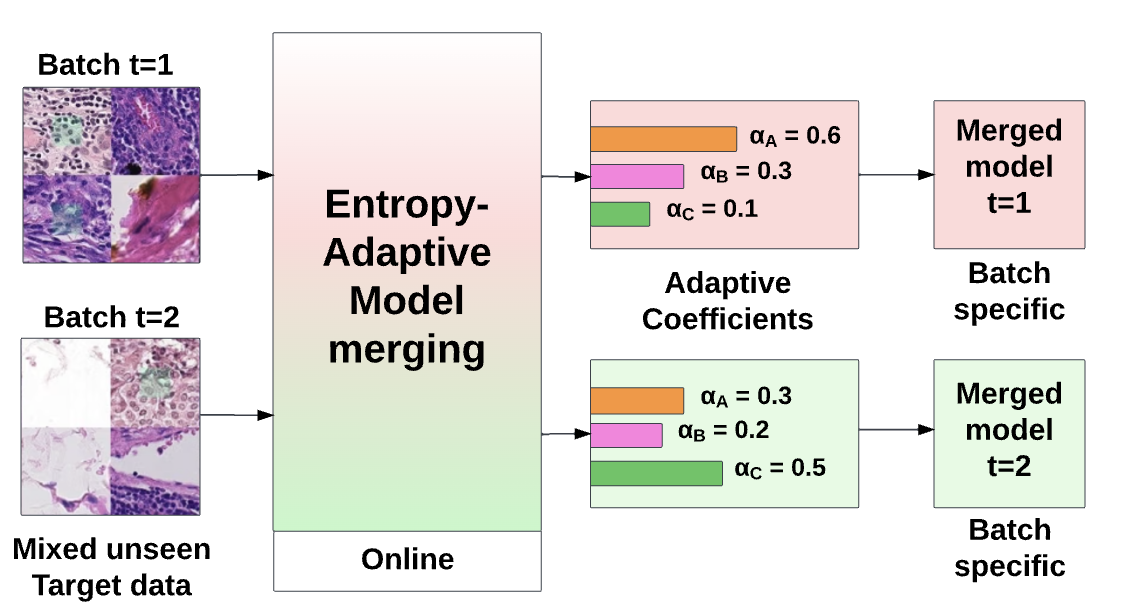
The Mean is the Mirage: Entropy-Adaptive Model Merging under Heterogeneous Domain Shifts in Medical Imaging
We demonstrate why mean merging is prone to failure and misaligned under heterogeneous domain shifts. Next, we mitigate encoder classifier mismatch by decoupling the encoder and classification head, merging with separate merging coefficients.
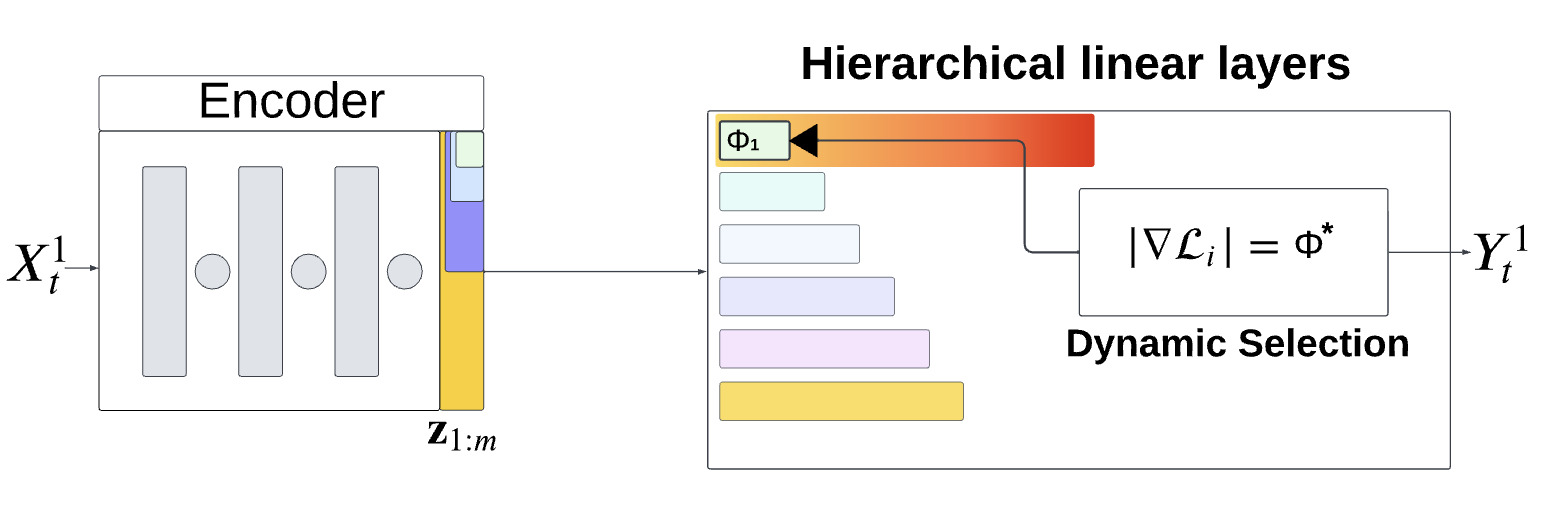
Hierarchical Adaptive networks with Task vectors for Test-Time Adaptation
We propose Hierarchical Adaptive Networks with Task Vectors (Hi-Vec), which leverages multiple layers of increasing size for dynamic test-time adaptation. By decomposing the encoder's representation space into such hierarchically organized layers, Hi-Vec, in a plug-and-play manner, allows existing methods to adapt to shifts of varying complexity. Our contributions are threefold: First, we propose dynamic layer selection for automatic identification of the optimal layer for adaptation to each test batch. Second, we propose a mechanism that merges weights from the dynamic layer to other layers, ensuring all layers receive target information. Third, we propose linear layer agreement that acts as a gating function, preventing erroneous fine-tuning by adaptation on noisy batches.
Precise Test-time detection
Test-Time adaptation: Non-Parametric, Backprop-free and entirely feedforward
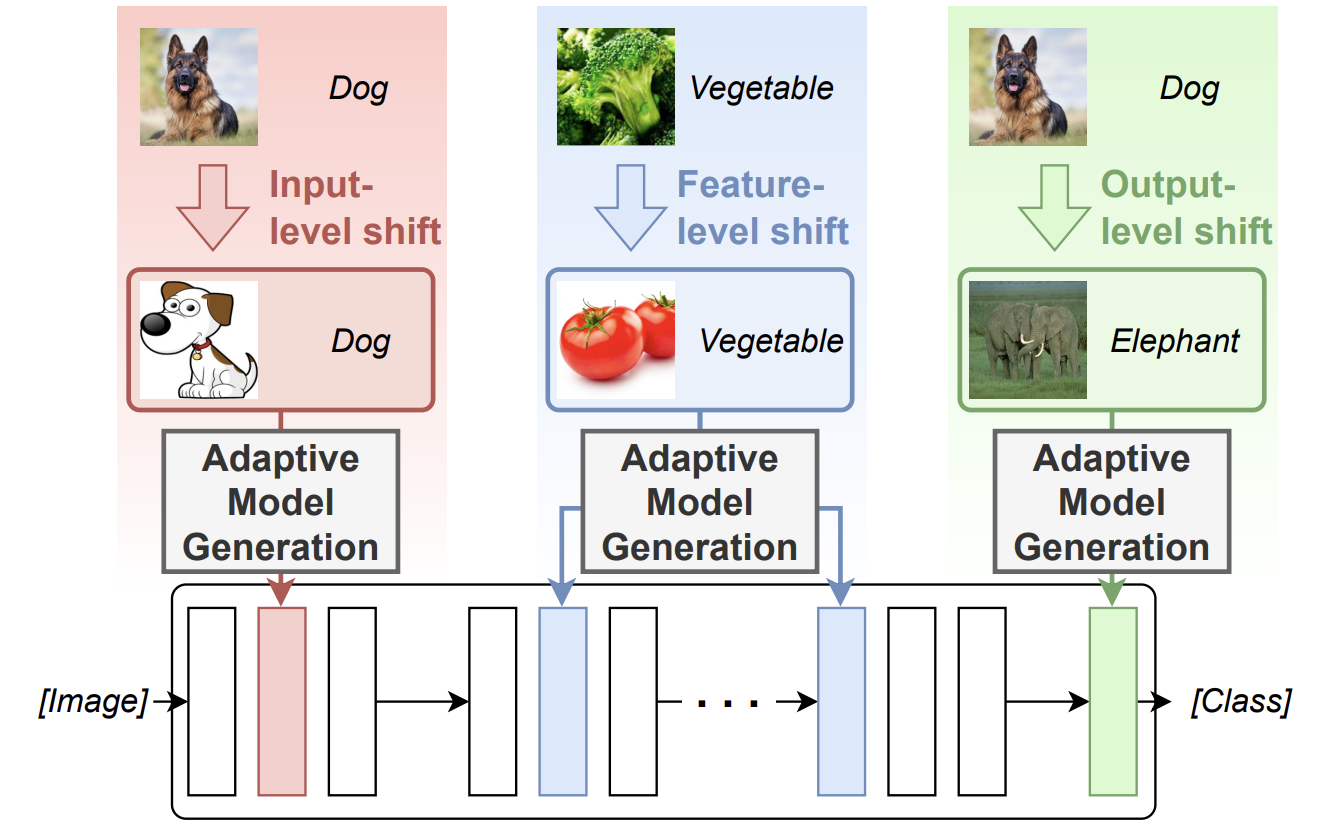
GeneralizeFormer: Layer-Adaptive Model Generation across Test-Time Distribution Shifts
We consider the problem of test-time domain generalization, where a model is trained on several source domains and adjusted on target domains never seen during training. Different from the common methods that fine-tune the model or adjust the classifier parameters online, we propose to generate multiple layer parameters on the fly during inference by a lightweight meta-learned transformer, which we call GeneralizeFormer.
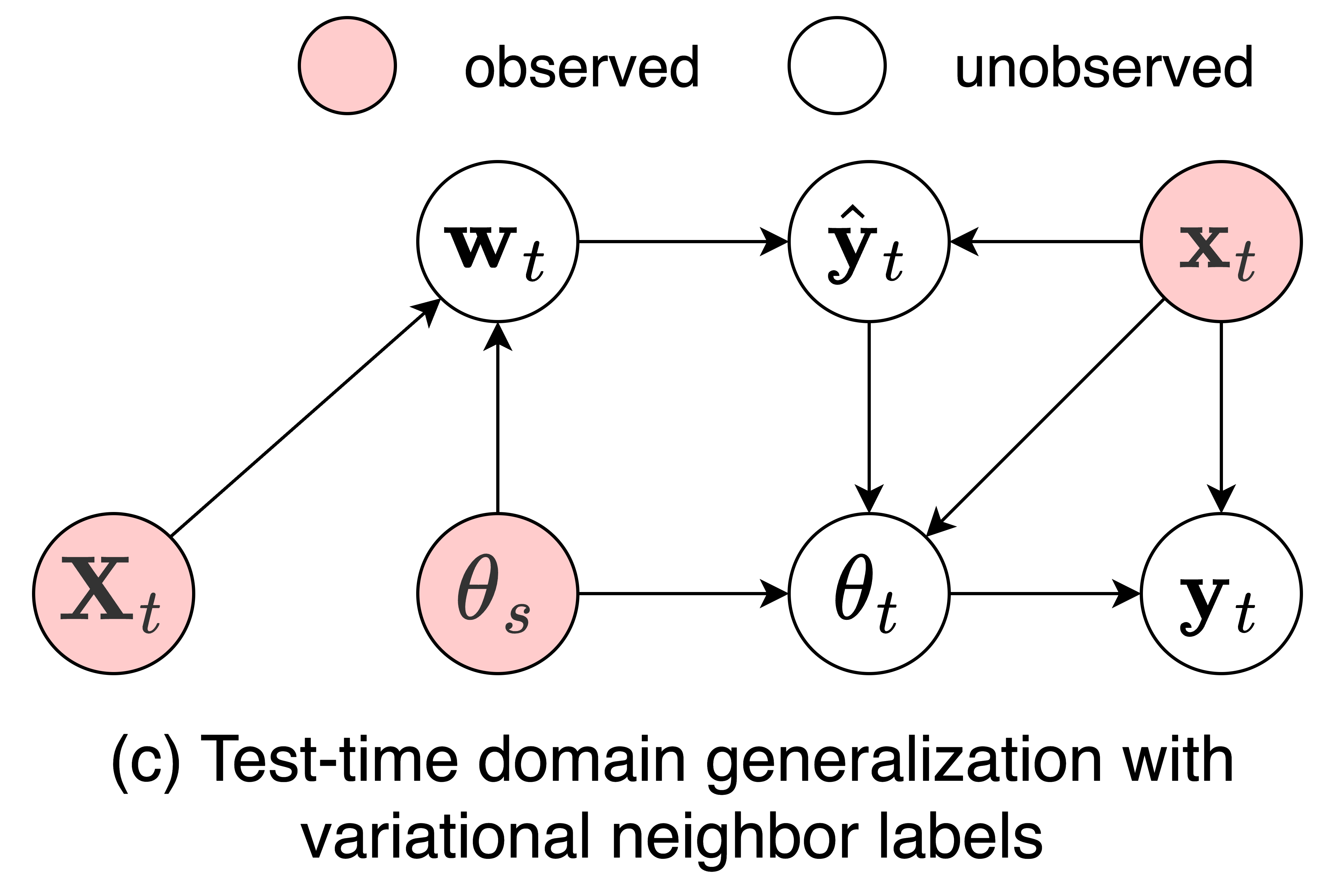
Probabilistic Test-Time Generalization by Variational Neighbor-Labeling
First, we propose probabilistic pseudo-labeling of target samples to generalize the source-trained model to the target domain at test time. We formulate the generalization at test time as a variational inference problem by modeling pseudo labels as distributions to consider the uncertainty during generalization and alleviate the misleading signal of inaccurate pseudo labels.
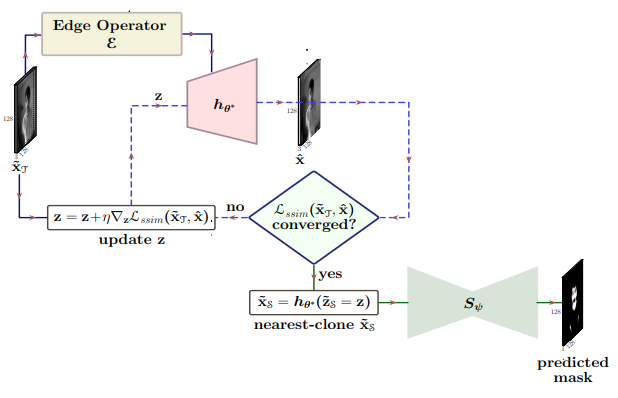
Unsupervised Domain Adaptation for Semantic Segmentation of NIR Images through Generative Latent Search
We cast the skin segmentation problem as that of target-independent Unsupervised Domain Adaptation (UDA) where we use the data from the Red-channel of the visible-range to develop skin segmentation algorithm on NIR images. We propose a method for target-independent segmentation where the 'nearest-clone' of a target image in the source domain is searched and used as a proxy in the segmentation network trained only on the source domain.
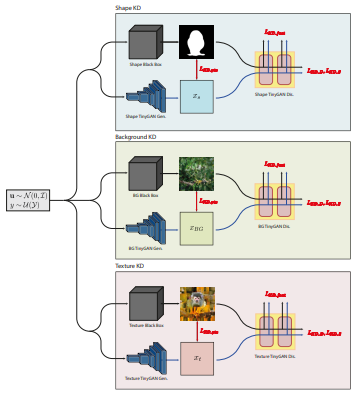
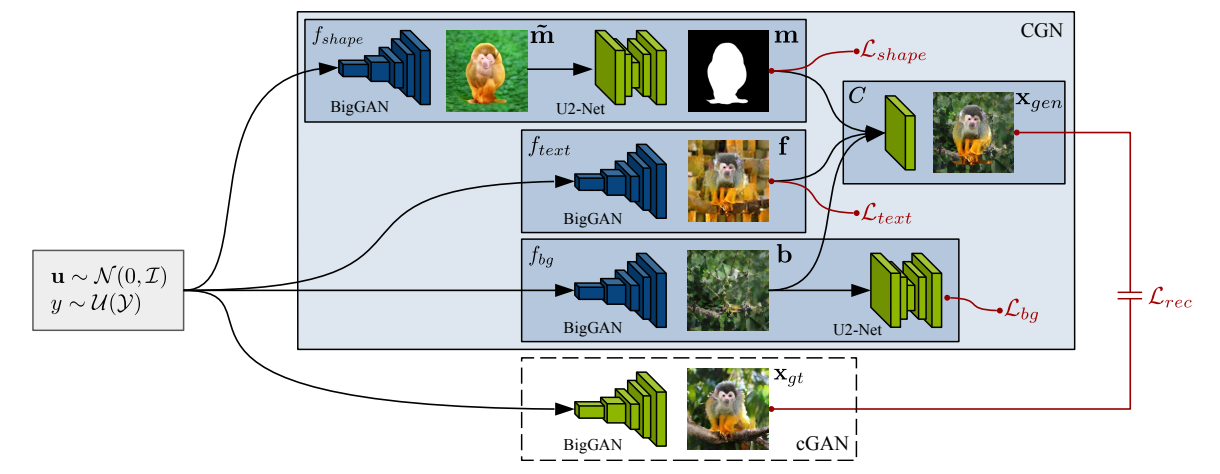
SKDCGN: Source-free Knowledge Distillation of Counterfactual Generative Networks using cGANs
We propose a novel work named SKDCGN that attempts knowledge transfer using Knowledge Distillation (KD). In our proposed architecture, each independent mechanism (shape, texture, background) is represented by a student 'TinyGAN' that learns from the pretrained teacher 'BigGAN'.
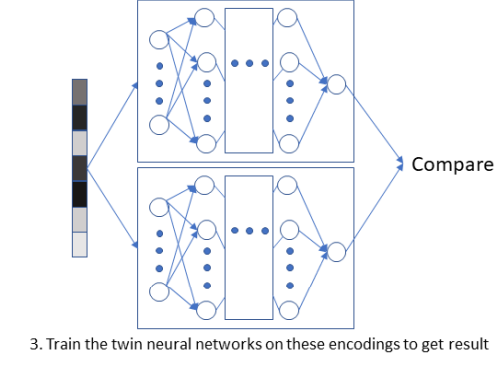
Twin Augmented Architectures for Robust Classification of COVID-19 Chest X-Ray Images
We introduce a state-of-the-art technique, termed as Twin Augmentation, for modifying popular pre-trained deep learning models. Twin Augmentation boosts the performance of a pre-trained deep neural network without requiring re-training.
Education
University of Amsterdam, Research Masters in Artificial Intelligence (MSc AI)
September 2021 - June 2023
I pursued my MSc thesis (48ECTS, Grade: Excellent) to
address Test-time Adaptation for Domain Generalization by proposing 2 methods: (i) Formulating it as a
Variational Inference problem and meta-learn Variational neighbor labels in a probabilistic framework
alongside exploring neighborhood information (ii) Surrogate update of the model without backpropagation.
Courses enrolled: Curriculum based and Research based.
Research Experience
University of Amsterdam, AIM Lab - Research Intern (Deep learning, Computer Vision)
June 2022 - June 2023
Indian Institute of Technology Delhi (IITD), Delhi, India - Research Assistant (Deep learning, Computer Vision)
January 2019 - July 2021
Indian Council of Medical Research (ICMR) NITM Bioinformatics Division, Belgaum, India - Research Trainee
October 2017 - December 2018

DbCom Inc., New Jersey, USA - Remote Intern
June 2015 - December 2016
Scholarships

Recipient of DigiCosme Full Master Scholarship, Université Paris-Saclay, France.
Activities & Leadership

Oxford Machine Learning Summer School (OxML 2020 & OxML 2022), Deep Learning - University of Oxford

PRAIRIE/MIAI PAISS 2021 Machine Learning Summer Learning - INRIA, Naver Labs

Regularization Methods for Machine Learning 2021 (RegML 2021) - University of Genoa

As a part of my recreational activity, I like to play the Indian Flute.
Rotaract Club of GIT
- • Charter Secretary
- • President
He makes good websites
Last updated: